![Each AI [ChatGPT, Perplexity, Google] Uses Keywords and Emotional Intent Differently](https://getheard.online/wp-content/uploads/2025/04/email-22-1024x576.jpg)
Did you know that text-based generative AI uses public Internet-sourced information in two ways? First, to learn, and second, to answer questions.
The mechanics behind each mechanism are rather complex; however, suffice it to say that in both cases, the AI converts everything that it receives into numbers before learning from or generating responses to requests.
These numbers enable the AI to understand the semantics of a spoken language and so predict the best response.
It’s very similar to the practice of Semantic SEO and the creation of Text Embeddings.
This means that AI and how it understands and behaves are highly susceptible to the information it is given and how it communicates to those who use these services.
In our research, we have learned that ChatGPT leans toward a broad expanse of emotional sentiment in the responses it provides, drawing upon Love, Fear, Anger, and Sadness. In contract, Perplexity and Google adopt differing approaches; however, both lean toward love.
Keep reading; all will make sense, I promise.
Why Understanding Each AI is Key to Maximizing Visibility
During training, the quality, veracity, and breadth of information will directly determine how the AI responds when a consumer engages.
If we feed the AI intense and dramatic material, it will have a strong bias toward this view. However, if we feed the AI scripts of happy, positive cartoons, the model will behave incredibly differently.
The differentiation continues right through to how it responds to a consumer. All responses were heavily biased toward the data that they learned from.
I ran an experiment contrasting ChatGPT 4o with Perplexity and Google AI Overviews to demonstrate my point.
I posted the same question to each. There is no prompt engineering or output cleverness, just the sentence:
What is the best business credit card?
I took the output of each response and passed them independently to two AIs: keyword extraction (using Amazon Comprehend) and emotion detection (Vern AI).
The results were as follows:
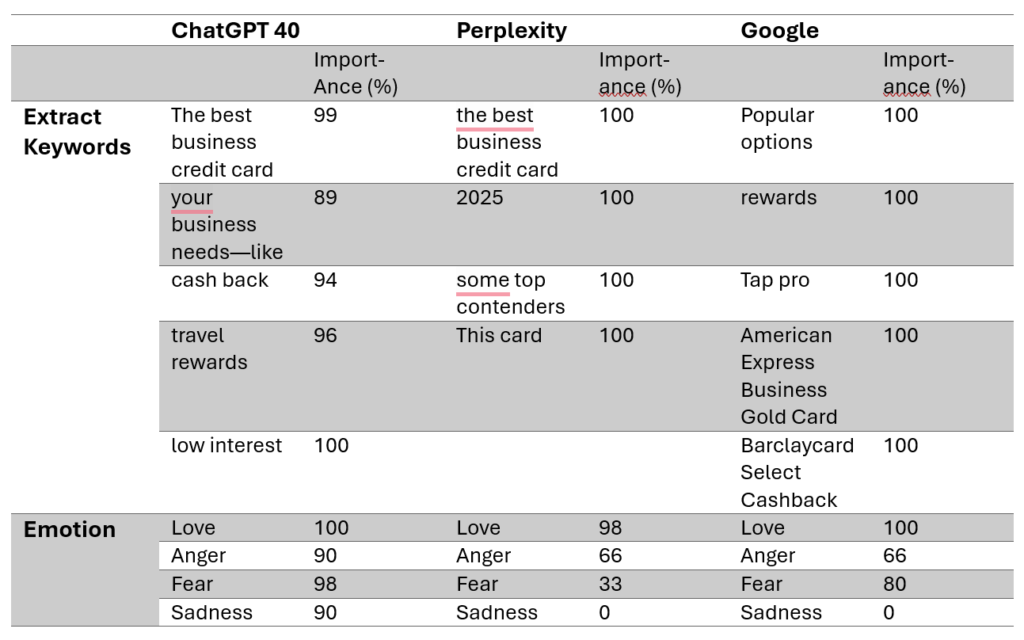
Without transformation, the results (appended to the foot of this article) were passed individually to each AI. A single AI was used for keyword extraction (in this case, Amazon’s Comprehend).
Interestingly, Google’s output was the only one that solicited brand and product names. In addition, ChatGPT’s response presented a varied, albeit high-scoring set of keywords. Perplexity was perhaps the most vague, especially as the year 2025 won equal weighting to the other keywords extracted from the text.
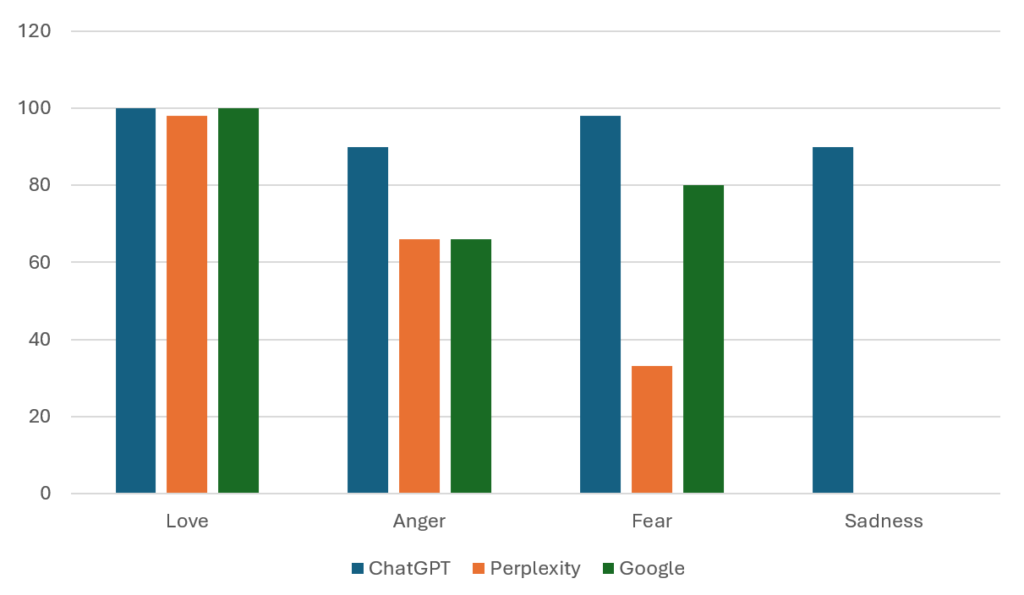
The emotional results were surprising. There were a lot of parallels between Google and Perplexity, and I cannot help but believe that this reflects a desire to be a search engine rather than a personal advisor.
However, the ChatGPT response included clear signals across all emotions.
So what gives?
The score presented by the Vern AI for emotion can be understood as follows:
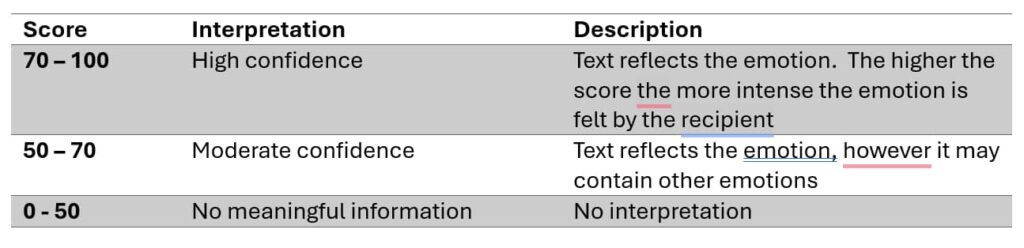
In other words, Vern AI reports that a score between 60 and 80 is a clear signal that the emotion is being conveyed.
If we take a step back, look at how each AI responded to the question.
Perplexity
Perhaps the most concise and detailed response was also the shortest. However, in my view, its answer was also the most complex to absorb. Both ChatGPT and Google opted for a bulleted layout that presented information in a quick-to-read format.
In contrast, Perplexity leverages a descriptive quality about the text it generated.
ChatGPT
It presents information in a bulleted format, organizing the results based on the capabilities of each credit card and business type. The original text leverages emojis and bold settings to highlight different aspects.
It is similar to the ChatGPT response but focuses solely on business type.
Are not all Generative-AI tools taught using public Internet data?
When you create a model, the process involves multiple steps, starting with reading web pages, extracting text, building a vocabulary, creating an association between each word in the vocabulary, and then refining it to ensure that the model’s interpretation aligns with the desired output.
While the process is known, the details of how each vendor (OpenAI, Google, and Perplexity) builds their model are secret.
Suffice it to say that differentiation is born from the many ways a vendor can read data, train a model, and develop its algorithm.
From a brand perspective, designing an approach to build Generative Engine Optimization (GEO) into an existing SEO strategy must be multi-faceted.
As if SEO weren’t complex enough, today’s SEO strategists will need to understand the nuances of each model to successfully compete for visibility.
As a closing thought, I passed each AI response through a process called Named Entity Recognition using the XAI Grok 2 model, and here’s what popped out.


