
In the late 1990s, I worked in Palo Alto. Just around the corner was Netscape, which I thought was uber cool.
My go-to search engine was Altavista, although I knew people who had started using something new, Google. Its simplicity starkly contrasted with the competition, and I remember it offering better results than the competition. That was 1998.
Twenty-plus years later, Generative AI, through Open AI, went mainstream, heralding a wave of competitors from Claude, Llama, and Deep Seek.
I started working in artificial intelligence in 2018. I thought that the technology would be a game changer for business. At the time, I wasn’t thinking about its application in search. Twelve months ago, however, I started to formulate an idea where GPTs could be used for internet search, albeit from a historical snapshot perspective.
This got me thinking. Search engines have been developed and evolved over twenty years. GPTs have been trained on public data for about seven years (Open AI was started in 2015), growing in complexity, but they were still not designed from the outset as an internet search engine.
Since then, various acronyms have sprung up: Search Generative Experience (SGE), Generative AI Optimization (GAIO), and Generative Engine Optimization (GEO), to name three. The last two attempt to position the idea of influencing a GPT like SEO does for traditional search.
If, like me, you have been involved in the SEO industry, the default approach to tackling GEO is to leverage existing tools and techniques to ensure brand visibility within AI-Overview responses and AI-search results.
I have concluded that SEO isn’t dead. It is as essential now in the Generative AI world as ever before.
However, my experience with AI and how AI models are trained tells me that traditional SEO strategies will not be enough to succeed in the future of Generative AI. It is worth noting that Gartner reported that by 2026 25% of search will shift to AI chatbots and other virtual agents.
With all this in mind, the following is a high-level overview of the large language models (LLM) that power Generative AI. The content is somewhat nerdy, but bear with me. Understanding how LLMs work will help you design strategies to influence them.
What are Large Language Models (LLM)?
All AI ever can solve two types of problems:
- Pattern generation
- Prediction
AI uses the data we provide to learn and predict or generate patterns. It can only do what people can do manually, albeit more slowly. Behind the scenes, there is no magic, just mathematics.
At the heart of AI is a model. A model is a collection of numbers organized in columns and rows called a matrix. These are the same matrices you would have worked with in a high school math class.
The method of creating a matrix is called training, which is an iterative process in which a mathematical algorithm is repeatedly given an input and performs some math to produce an output. The training “iterative” process, creating many different versions, continues until the math identifies that the model’s ability to predict a desired outcome based on a known input is the best it will ever be.
Once trained, the model never changes. It is read-only.
Predicting is called inference. Given an input, the model is used to infer a response.
This is an important point, a model:
- Can only infer one output value at a time.
It is deterministic. Given the same input, the output will always be the same.
How LLMs Learn and How Can We Influence Them?
I will no doubt have Data Scientists pulling out their hair after reading my explanation of the AI training process; however, at a very high level, this is how it works.
Training a GPT is somewhat more complex; however, the process is roughly the same.
Many of us have used a GPT like ChatGPT. We’ve typed in some text to the GPT and watched with excitement as the response appeared.
When you click the submit button in ChatGPT, for example, the GPT uses a model called a Large Language Model (LLM). The submitted text is technically called the Context (more on later).
The LLM training process involves creating a neural network, which is a collection of interconnected mathematical functions organized in layers. The process builds a vocabulary of words (for the sake of this high-level overview, in the GPT world, words are also known as tokens) and identifies (in relation to the text/data that the LLM was trained on) to what degree each word is related to each other.
Each layer is called an embedding, and there are many types, all performing a different task. In the case of an LLM, we have embedding layers called Attention Embedding Layers, whose job is to influence the degree to which each word in a vocabulary relates to the context.
Check out the image below, which depicts the word “Tower” with different towers: Eiffel, Leaning, and Scottish.
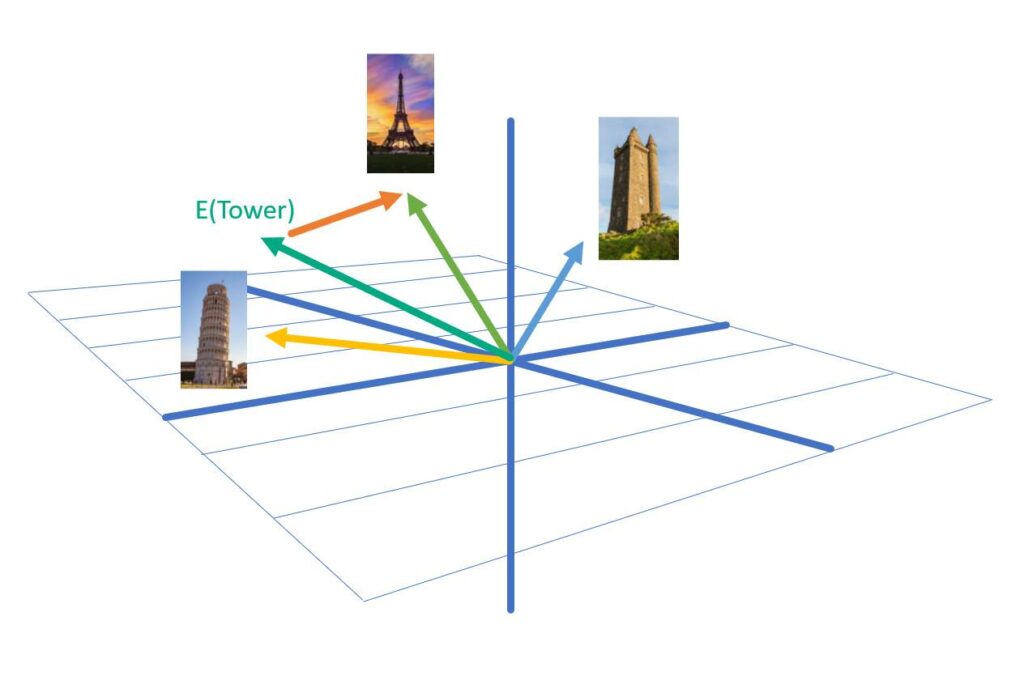
If we start with the context “How tall is the Eiffel Tower?” during inference, attention influences the next word to appear in the series. That is, from a probability perspective, what is the most likely next word to occur after the question mark?
In other words, the goal of training is to forge bridges between tokens in the vocabulary and the most likely next token in a sequence.
This means the larger the vocabulary, the better (there’s a but – hallucinations).
How LLMs Process Information: How does an LLM learn?
Let’s say our training material has the following three lines:
- I like digital cameras
- I like Sony digital cameras
- You like Sony
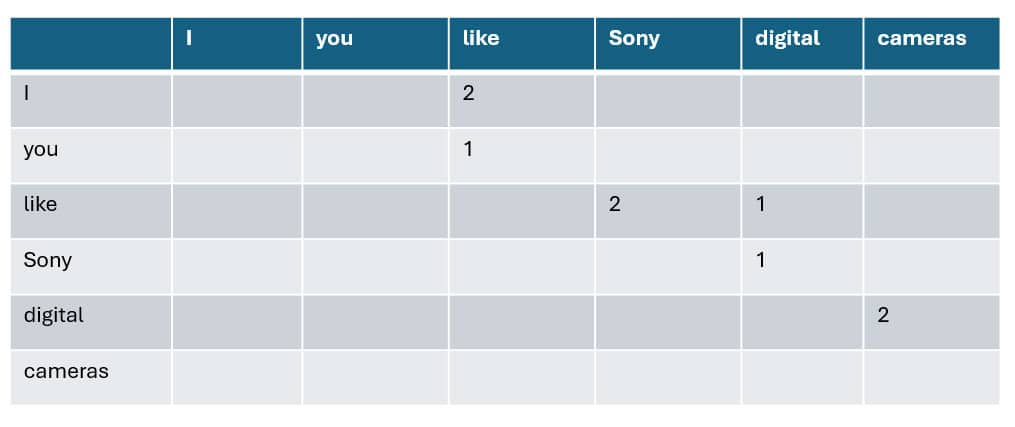
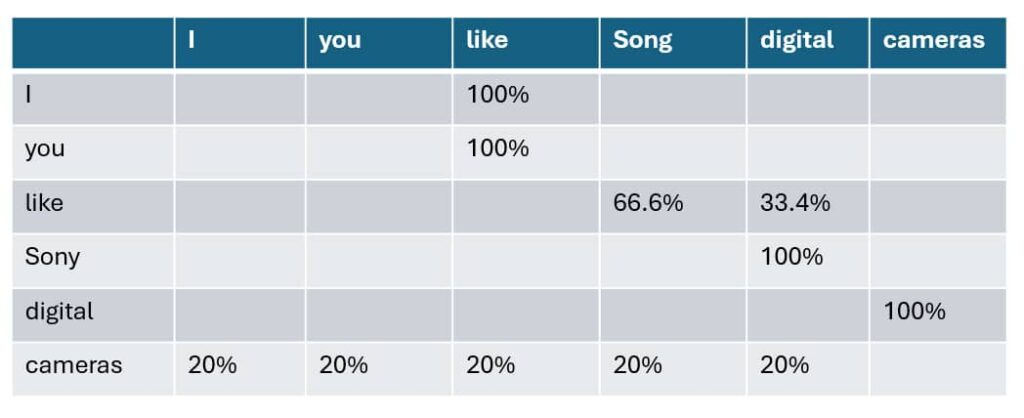
The training starts by building a table describing the frequency with which each token combination pair is found across all training data.
For example, as presented in the following table, the word “I” is followed by “like” two times, and so the number two is placed at the intersection of “I” and “like.” In all cases, the first token in the pair is the row, and the second token is the column.
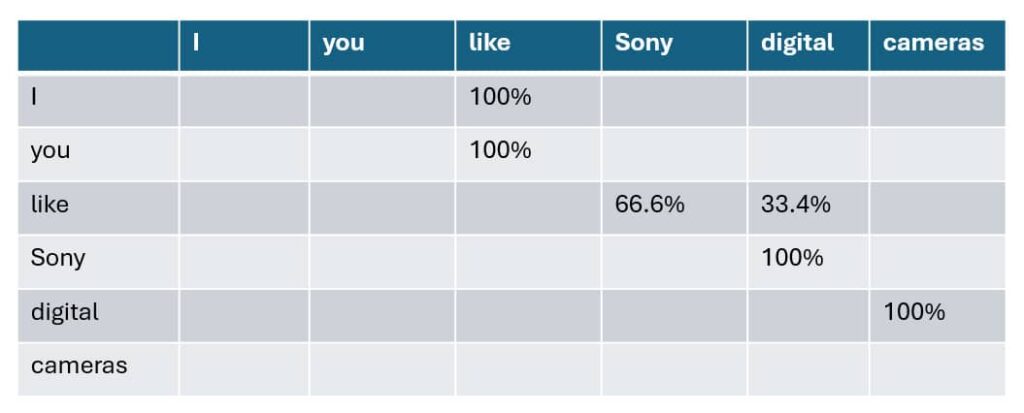
Next, and as seen in the following table, the training process calculates the probability of each follow-on token for each row using the first table as input.
In the training data, the token “I” is only ever followed by the token “like”, so there is a 100% probability that like will follow I.
In contrast, the token “like” is followed by the tokens “Sony” and “digital”. In this case, the frequency at which each follow-on token follows the row determines the probability. In the case of “like”, the token “Sony” followed “like” twice (or 66.6%) of the time when compared to “digital”, 33.3% of the time.
What about the token “camera”? It doesn’t have any probability assigned to it.
I’m glad you asked; this is why GPTs hallucinate.
When the training data does not provide follow-on information for a token, the training process assigns equal probability to all possible follow-on tokens to ensure that the model will work in all cases.
If we infer a context like “Tell me about cameras” without assigning any follow-on probabilities to the token “cameras,” the LLM would be unable to respond.
Remember that models, once trained, are read-only and deterministic. If the probability data doesn’t exist, the model will not be able to predict the next token in the sequence.
Providing complete data is a key step to ensure that the model predicts as we want it to
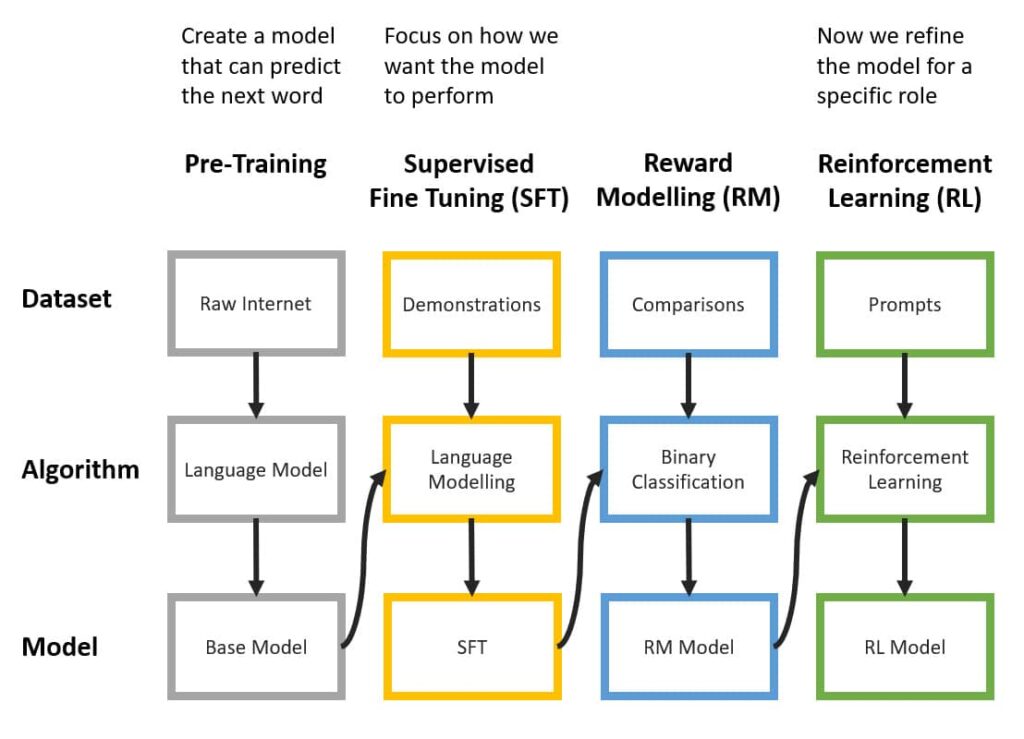
The LLM training process has the following steps. This is perhaps more detail than you need to know, but I have included it here for completeness.
Difference Between Traditional SEO and LLM-Based Search
I hope that you now have a working knowledge of how an LLM works.
In contrast to a search engine like Google, which works by crawling, indexing, and ranking websites, an LLM doesn’t do any of these things.
Given a context, an LLM uses its vocabulary and attention to predict the most likely next token/word in the sequence.
It is highly influenced by the quality of the data it is trained and how the context aligns with its vocabulary.
So, how does a GPT search the Internet? Remember that the model is deterministic and can only predict one token at a time.
It can’t search the internet. The inference process that calls the model does. The inference process can use a traditional search engine to narrow down the likely websites whose content matches the context. The content of the websites is added to the context before being passed to the model for prediction. The model predicts a single token whose quality is determined by the inference process.
This process is repeated, with the model called multiple times. On each iteration, the previously accepted model output is added to the context to predict the next token in the sequence.
Conclusion
GEO is not a replacement for SEO but an extension of it.
The trick to GEO is to learn how the model was trained, what vocabulary and attention it has, and how the inference process works.

